

This whitepaper highlights an important yet often overlooked aspect of cough monitoring: the data processing architecture that supports how cough events are detected and reported in clinical trials. As pharmaceutical sponsors increasingly include cough as a digital endpoint in clinical trials, the choice between edge processing (analysis on-device in real-time, typically by machine learning) and cloud processing (analysis of raw data on secure servers using a combination of machine learning and human analysis) has significant implications for scientific integrity and regulatory acceptance.
Download the Full Whitepaper:
Edge Processing
Edge-based systems analyze patient data locally on a wearable, providing immediate outputs and reducing data transmission needs. These features can be advantageous in low-connectivity environments or for consumer wellness applications. However, in the context of cough monitoring in clinical trials, edge processing has certain limitations:
- No access to raw audio for quality control, re-review, or audit
- Automated-only outputs with no option for human annotation or review
- Regulatory uncertainty, since FDA gold standard for 24-hour cough frequency relies on human annotation
- Limited ability for comprehensive and contextual analysis of patient data
- Inability to review potential errors in noisy environments
These constraints raise concerns about transparency, accuracy and reproducibility when edge-only processing is used for digital endpoint collection in clinical trials.
Cloud Processing
Rather than analyzing data immediately and directly on the device, cloud-based architectures transmit raw audio to secure servers for analysis later, enabling a more flexible and comprehensive overread of data. This model preserves auditability and supports multiple methods of cough counting, including human, semi-automated, or fully automated, depending on study requirements.
Key advantages include:
- Full raw data retention, ensuring scientific auditability and reproducibility
- Regulatory defensibility, with transparent audit trails aligned with primary endpoint requirements
- Multi-annotator review and adjudication for quality assurance
- Ability for comprehensive analysis, including contextual endpoints (e.g., cough frequency during wheeze events or sleep)
- Iterative machine learning development, using large, diverse real-world datasets
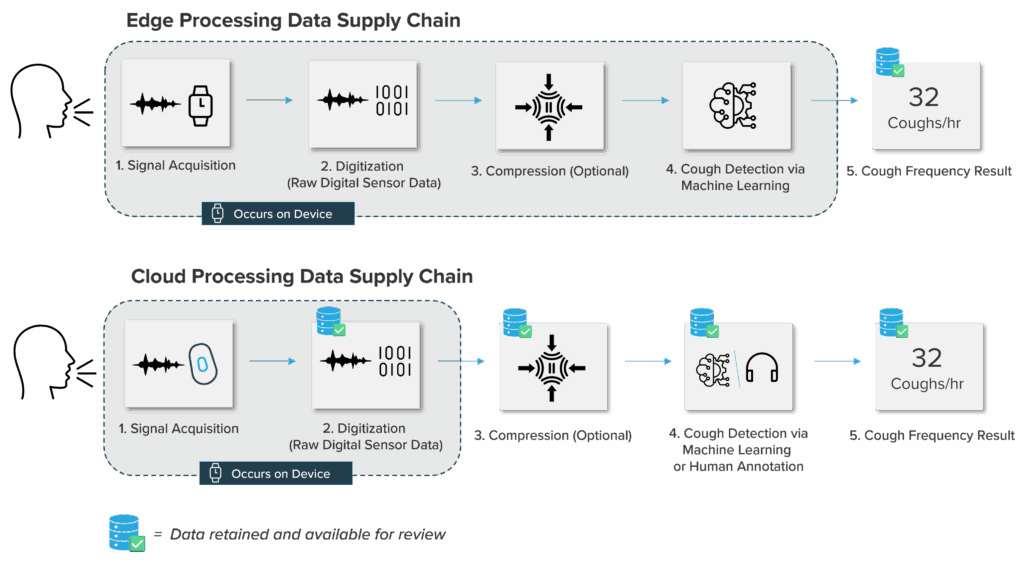
Image 1: Data Supply Chains for Edge Processing and Cloud Processing
Privacy and Participant Trust
The whitepaper also addresses privacy concerns about storing raw audio in the cloud. Privacy-preserving strategies, such as speech obfuscation filters, random file segmentation, and encryption, ensure that sensitive information is protected while preserving cough fidelity. Importantly, certain devices such as the RESP® Biosensor are designed to capture internal lung sounds rather than external audio that help preserving patient privacy.
Implications for Clinical Trials and Digital Endpoints
For pharmaceutical sponsors, the choice of architecture directly impacts the regulatory defensibility of cough endpoints. Without raw audio, it is impossible to conduct audits, resolve discrepancies, or validate machine learning algorithms against the FDA-recognized gold standard of human annotation. Cloud-based systems ensure that trial data meet regulatory expectations for transparency, auditability, and reproducibility.
Conclusion
By retaining and analyzing raw audio, cloud architectures provide the scientific rigor, flexibility, and regulatory compliance necessary to establish cough monitoring as a trusted, defensible digital endpoint in drug development.
Authors

Jason Kroh
Chief Technology Officer, Strados Labs

Tom deLaubenfels, PhD
Director of Data Science, Strados Labs